
در دنیای دیجیتال امروزی، تقریبا همه افراد از خود ردپای دیجیتال بهجا میگذارند. از سبک زندگی، فعالیتهای ورزشی و سفرها گرفته تا علایق و سرگرمیها. در حقیقت تعامل روزانه ما با انبوهی از دستگاههای متصل به اینترنت، حجم بسیار زیادی از دادهها را درباره ما تولید میکند. این حجم انبوه و متنوع از دادهها با عنوان “کلانداده” یا “داده های بزرگ” (Big Data) شناخته میشود.
تعریف بیگ دیتا
شرکت Ernst & Young کلانداده را اینگونه تعریف میکند:
«کلانداده به مجموعههای بسیار بزرگ، متنوع و در حال تغییر دادهها اطلاق میشود که از سوی انسانها، تجهیزات و ماشینها تولید میشوند. تحلیل این دادهها نیازمند فناوریهای نوآورانه و مقیاسپذیر برای جمعآوری، ذخیرهسازی و پردازش است؛ بهطوریکه بتوان در زمان واقعی (Real-Time) به بینشهایی کاربردی در حوزههایی همچون رفتار مصرفکننده، مدیریت ریسک، بهبود عملکرد، سودآوری و بهرهوری دست یافت.»
با اینکه تعریف دقیق و یکسانی برای کلانداده (Big Data) وجود ندارد، اما تقریبا همهی تعاریف موجود روی پنج ویژگی کلیدی تأکید دارند که به عنوان 5V کلانداده شناخته میشن:
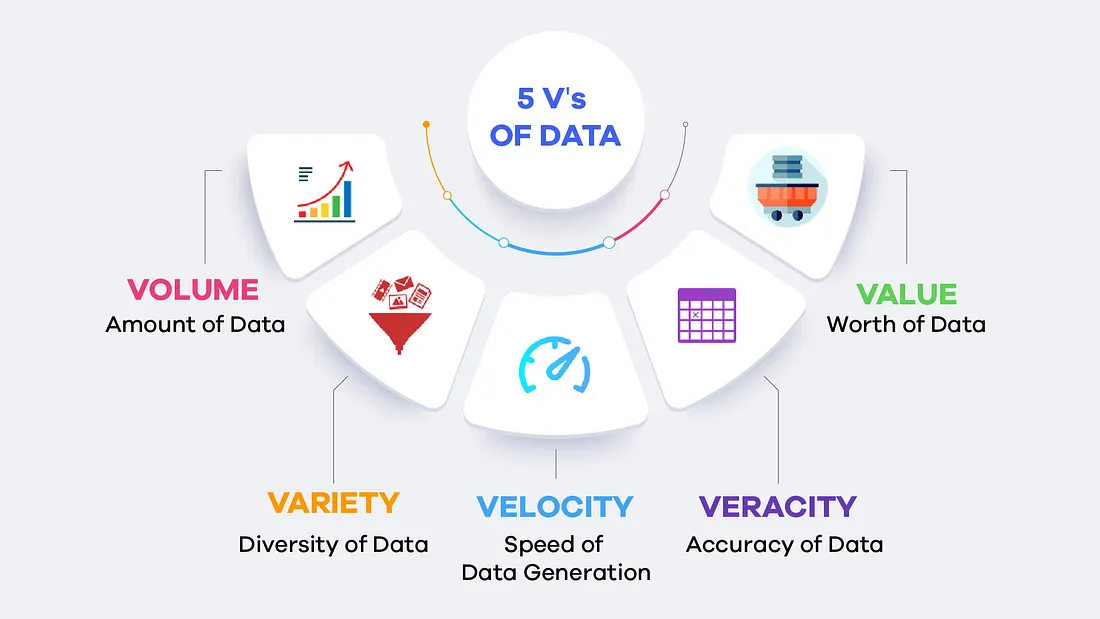
سرعت (Velocity)
منظور، سرعت بالای تولید و جریان دادههاست. در دنیای امروزی، دادهها بهصورت مداوم و لحظهای تولید میشن — مثلاً از سنسورها، شبکههای اجتماعی یا تراکنشهای آنلاین. فناوریهایی مثل پردازش استریم و رایانش ابری کمک میکنن این دادهها در لحظه پردازش و تحلیل بشن. برای مثال هر 60 ثانیه، ساعتها ویدئو در یوتیوب آپلود میشود.
رایانش ابری (cloud computing) یعنی استفاده از منابع کامپیوتری (مثل سرورها، ذخیرهسازی، دیتابیسها، نرمافزارها و…) از طریق اینترنت، بدون اینکه نیاز باشد سختافزار یا زیرساخت فیزیکی را خودمان تهیه و یا نگهداری کنیم.
چند ویژگی مهم رایانش ابری:
- مقیاسپذیری (Scalability): هر وقت نیاز داشتی، میتونی منابع بیشتری بگیری یا اونا رو کاهش بدی — کاملاً انعطافپذیره.
- پرداخت به اندازه مصرف (Pay-as-you-go): فقط به اندازهای که استفاده میکنی، هزینه میدی. مثل قبض برق.
- عدم نیاز به سختافزار فیزیکی: همهچیز روی سرورهای ارائهدهندگان ابری (مثل AWS، Google Cloud، Azure، IBM Cloud و…) اجرا میشه.
- دسترسی از هرجا: فقط با اینترنت، از هرجایی که باشی به دادهها و نرمافزارهات دسترسی داری.
رایانش ابری در علم داده
در پروژههای دادهمحور، مخصوصا وقتی حجم دادهها زیاد هست یا نیاز به قدرت پردازشی بالا داریم، رایانش ابری بهترین گزینهست. مثلاً برای:
- ذخیرهسازی کلاندادهها در Data Lake یا Data Warehouse
- اجرای الگوریتمهای یادگیری ماشین یا یادگیری عمیق روی سرورهای قدرتمند
- ساخت داشبوردهای تحلیلی
- پردازش دادههای جریانی (Streaming Data): یکی از روشهای بسیار مهم و کاربردی در دنیای کلانداده (Big Data) هست که اجازه میده دادهها همزمان با تولید و ورود، بهصورت بلادرنگ (Real-time) پردازش بشن.
حجم (Volume)
حجم عظیم دادهها یکی از بارزترین ویژگیهای کلاندادهست. بهدلیل گسترش منابع دادهای (مثل IoT، موبایل، رسانههای اجتماعی و …) و وجود زیرساختهای مقیاسپذیر مثل دیتا لیکها، حجم دادهها به طرز چشمگیری رشد کرده است. برای مثال جمعیت جهان حدود 7 میلیارد نفر است و بیشتر افراد از دستگاههای دیجیتال استفاده میکنند که روزانه 2.5 کوینتیلیون بایت داده تولید میکنند (معادل 10 میلیون دیویدی بلوری).
تنوع (Variety)
دادهها میتونن از نوع ساختاریافته (مثل دادههای موجود در دیتابیسها) یا غیرساختاریافته (مثل تصاویر، ویدئوها، متون شبکههای اجتماعی) باشند. ترکیب این انواع داده از منابع داخلی و خارجی، تحلیل دادهها رو چالشبرانگیزتر اما ارزشمندتر میکند.
صحت (Veracity)
یعنی کیفیت، دقت و قابلاعتماد بودن دادهها. دادههایی که نویز دارن، ناقص هستن یا بهدرستی برچسبگذاری نشدن، میتونن باعث تحلیلهای اشتباه بشن. به همین دلیل، پاکسازی داده (Data Cleaning) بخش مهمی از پروژههای دادهمحوره. برای مثال حدود 80 درصد دادهها غیرساختاریافتهاند و نیاز به روشهایی برای استخراج اطلاعات دقیق و قابل اعتماد دارند.
ارزش (Value)
دادهها زمانی ارزشمند میشن که ازشون بینش (Insight) استخراج بشه. این ارزش میتونه در زمینههای مختلفی مثل بهبود تجربه مشتری، افزایش بهرهوری، نوآوری در پزشکی یا حل مسائل اجتماعی نمود پیدا کند و عموما با ابزارهایی مانند Apache Spark و Hadoop پردازش میشود.
رویکرد جدید در پردازش کلان داده ها
در گذشته، دادهها به طور مستقیم وارد کامپیوترها میشدند، اما در سیستمهای خوشهای با حجم داده بالا، دادهها به بخشهای کوچکتر تقسیم شده و پردازش به صورت موازی بر روی چندین کامپیوتر انجام میشد. این فرایند که به روشهای “مپ” (Map) و “کاهش” (Reduce) شناخته میشود که امکان پردازش حجم بالای دادهها را به شکلی کارآمد فراهم میآورد. این روش طوری طراحی شده که با افزایش تعداد سرورها، میتوان به بهبود عملکرد بهطور خطی دست یافت. بعدها این معماری توسط یاهو و توسعهدهندگان پروژه Hadoop گسترش یافت.
اساس علم داده به دههها قبل برمیگردد، اما امروز ترکیب آمار، جبر، برنامهنویسی و پایگاههای داده با توان محاسباتی جدید باعث ظهور یادگیری ماشین شده است؛ به طوری که میتواند دادههای عظیم را تجزیه و تحلیل کرده و الگوهایی کشف کند که ممکن است به سوالات تحقیقاتی جدید منجر شود. این ترکیب از تکنیکهای سنتی و مدرن در علم داده تحت عنوان “علم تصمیمگیری” شناخته میشود. در سالهای اخیر، علم داده به سرعت پیشرفت کرده و به ابزاری اساسی برای تحلیل دادهها تبدیل شده است، به ویژه با ظهور یادگیری عمیق و شبکههای عصبی چند لایه که در شرکتهای بزرگ کاربردهای زیادی پیدا کرده است. در مقاله ای دیگر توضیح داده ام علم داده چیست و پیشنهاد می کنم آن را بخوانید.
فناوریهای پردازش دادههای بزرگ به روشهایی برای مدیریت و استخراج ارزش از مجموعههای عظیم دادههای ساختاریافته، نیمهساختاریافته و غیرساختاریافته تبدیل شدهاند. این فناوریها شامل سیستمهایی هستند که امکان پردازش و تحلیل دادهها را به شکلی مقیاسپذیر و توزیعشده فراهم میکنند. در این مقاله قصد داریم سه فناوری open source که در تحلیل دادههای بزرگ نقش دارند را معرفی کنیم: Apache Hadoop، Apache Hive و Apache Spark.
Hadoop یک مجموعه ابزار است که ذخیرهسازی و پردازش توزیعشده دادههای بزرگ را امکانپذیر میکند. Hive یک انبار داده برای پرسوجو و تحلیل دادهها است که بر روی Hadoop اجرا میشود. Spark یک چارچوب پردازش دادههای توزیعشده است که برای انجام تحلیلهای پیچیده به صورت stream طراحی شده است.
Hadoop، یک چارچوب open source مبتنی بر جاوا است که اجازه میدهد دادههای بزرگ در میان خوشههای کامپیوتری ذخیره و پردازش شوند. در این سیستم توزیعشده، هر “نود” معادل یک کامپیوتر است و مجموعهای از نودها یک خوشه را تشکیل میدهند. Hadoop این امکان را میدهد که از یک نود به تعداد زیادی نود گسترش یابد و هر نود وظیفه ذخیرهسازی و پردازش دادهها را بر عهده گیرد. این سیستم راهحلی مقیاسپذیر، قابلاعتماد و مقرون به صرفه برای ذخیرهسازی دادهها بدون نیاز به فرمت خاص فراهم میآورد.
یکی از چهار مؤلفه اصلی Hadoop، سیستم فایل توزیعشده (Hadoop HDFS) است که سیستمی برای ذخیرهسازی دادههای بزرگ است. این سیستم فایلها را به قطعات کوچکتر تقسیم کرده و آنها را در نودهای مختلف خوشه ذخیره میکند تا دسترسی موازی به دادهها ممکن شود. HDFS از تکثیر بلوکهای داده برای افزایش دسترسپذیری و مقاومت در برابر خطا استفاده میکند.
Hive، یک انبارopen source است که بهویژه برای خواندن، نوشتن و مدیریت دادههای بزرگ طراحی شده است و میتواند روی HDFS یا سیستمهای ذخیرهسازی دیگر مانند Apache HBase اجرا شود. Hive بیشتر برای کارهای انبار داده مانند ETL، گزارشدهی و تحلیل دادهها کاربرد دارد.
در نهایت، Apache Spark یک موتور پردازش دادههای توزیعشده است که برای تحلیل دادههای stream، پردازشstream، یادگیری ماشین و یکپارچهسازی دادهها طراحی شده است. Spark از پردازش در حافظه بهره میبرد تا سرعت پردازش را بهشدت افزایش دهد و در مواقع ضروری به دیسک منتقل میشود. این سیستم میتواند به منابع مختلف داده مانند HDFS و Hive دسترسی پیدا کند.

