
علم داده و هوش مصنوعی دو کلیدواژه محوری در دنیای امروز هستند. رابطه علم داده و هوش مصنوعی به این معناست که چگونه تکنیکهای پیشرفتهی تحلیل داده (علم داده) و الگوریتمهای خودیادگیر (هوش مصنوعی) با هم ترکیب میشوند تا الگوهای پنهان در دادهها را کشف و تصمیمگیریهای هوشمندانه را ممکن سازند. در ادامه، مهمترین مفاهیم و ابزارهای این دو حوزه را مرور میکنیم.
رابطه علم داده و هوش مصنوعی
در علم داده، اصطلاحات زیادی وجود دارند که بهطور جایگزین استفاده میشوند، پس بیایید رایجترین آنها را بررسی کنیم. اصطلاح «دادههای بزرگ یا بیگ دیتا» به مجموعه دادههایی اشاره دارد که آنقدر عظیم، به سرعت ساخته شده و متنوع هستند که روشهای سنتی تحلیلی مانند آنچه در پایگاههای داده رابطهای انجام میشود، قادر به پردازش آنها نیستند. توسعه همزمان قدرت محاسباتی عظیم در شبکههای توزیعشده و ابزارها و تکنیکهای جدید تحلیل داده به سازمانها این امکان را داده است که این مجموعههای داده عظیم را تحلیل کنند. دانش و بینشهای جدیدی برای همه در دسترس قرار میگیرند.
دادههای بزرگ اغلب از منظر پنج ویژگی یا «V» توصیف میشوند:
- سرعت (velocity)
- حجم (volume)
- تنوع (variety)
- صحت (veracity)
- ارزش (value)
داده کاوی فرآیند جستجو و تحلیل خودکار دادهها است تا الگوهای ناشناخته و کشف نشده شناسایی شوند. این فرآیند شامل پیشپردازش دادهها برای آمادهسازی آنها و تبدیل آنها به فرمتی مناسب است. پس از این مرحله، بینشها و الگوها با استفاده از ابزارها و تکنیکهای مختلفی از جمله ابزارهای ساده تجسم داده تا مدلهای آماری و الگوریتمهای یادگیری ماشین استخراج میشوند.
یادگیری ماشین، که زیرمجموعهای از هوش مصنوعی محسوب میشود، از الگوریتمهای کامپیوتری برای تحلیل دادهها استفاده میکند و بر اساس آموختهها بدون برنامهنویسی صریح تصمیمات هوشمندانه اتخاذ میکند. الگوریتمهای یادگیری ماشین با استفاده از مجموعههای داده بزرگ آموزش میبینند و از مثالها یاد میگیرند؛ آنها بر اساس قواعد از پیش تعیینشده عمل نمیکنند. یادگیری ماشین به ماشینها امکان میدهد تا به تنهایی مشکلات را حل کرده و پیشبینیهای دقیقی براساس دادههای ارائهشده انجام دهند.
یادگیری عمیق، زیرمجموعهای تخصصی از یادگیری ماشین است که از شبکههای عصبی لایهای برای شبیهسازی فرآیند تصمیمگیری انسانی بهره میبرد. الگوریتمهای یادگیری عمیق قادر به برچسبگذاری و دستهبندی اطلاعات و شناسایی الگوها هستند. این فناوری به سیستمهای هوش مصنوعی اجازه میدهد تا به طور مداوم در حین کار یاد بگیرند و کیفیت و دقت نتایج را با بررسی صحت تصمیمات بهبود بخشند.
شبکههای عصبی مصنوعی، که اغلب به سادگی «شبکههای عصبی» نامیده میشوند، از شبکههای عصبی زیستی الهام گرفتهاند، اگرچه روش کار آنها تفاوتهایی دارد. یک شبکه عصبی در هوش مصنوعی مجموعهای از واحدهای محاسباتی کوچک به نام نورون است که دادههای ورودی را دریافت کرده و با گذشت زمان یاد میگیرد چگونه تصمیمگیری کند. شبکههای عصبی معمولاً چند لایه هستند و به همین دلیل است که الگوریتمهای یادگیری عمیق با افزایش حجم داده کارایی بیشتری کسب میکنند، در حالی که الگوریتمهای دیگر یادگیری ماشین ممکن است با افزایش داده به سقف عملکرد برسند.
نقش ابزارهای هوش مصنوعی در مراحل چرخه علم داده
در هر مرحله از چرخه علم داده، ابزارهای هوش مصنوعی نقشی کلیدی ایفا میکنند؛ ابتدا با استفاده از Scikit-learn عملیات پیشپردازش و ویژگیسازی (Feature Engineering) بهصورت اتوماتیک و سریع انجام میشود، بهگونهای که دادههای ورودی پاکسازی، نرمالسازی و به فرمت مناسب تبدیل شوند.
سپس در مرحله مدلسازی، TensorFlow امکان ساخت و آموزش مدلهای پیچیده یادگیری ماشین و شبکههای عصبی را فراهم میآورد تا الگوهای پنهان در دادهها با دقت بالا شناسایی شوند. برای مسائل یادگیری عمیق، PyTorch با انعطاف در طراحی معماریهای چندلایه و قابلیت آموزش پویا، سرعت توسعه و آزمون مدلها را افزایش میدهد.
پس از آموزش مدل، با ابزارهای ارزیابی مانند ماژولهای ارزیابی عملکرد Scikit-learn، دقت، بازیابی (Recall) و معیارهای دیگر سنجیده شده و برای بهبود بیشتر بهینهسازی میشوند. در نهایت، با استفاده از قابلیتهای استقرار (Deployment) TensorFlow Serving یا TorchServe، مدلها به محیطهای تولیدی منتقل میشوند تا در سیستمهای عملیاتی واقعی، از پیشبینی رفتار مشتریان گرفته تا تشخیص تقلب بانکی، بهرهبرداری شوند.
این فرآیند جامع، نمونهای از رابطه علم داده و هوش مصنوعی است که نشان میدهد چگونه تلفیق ابزارهای AI با روشهای علم داده، راهکارهای جامع و اثربخشی را برای کسبوکارها و سازمانها ارائه میدهد.
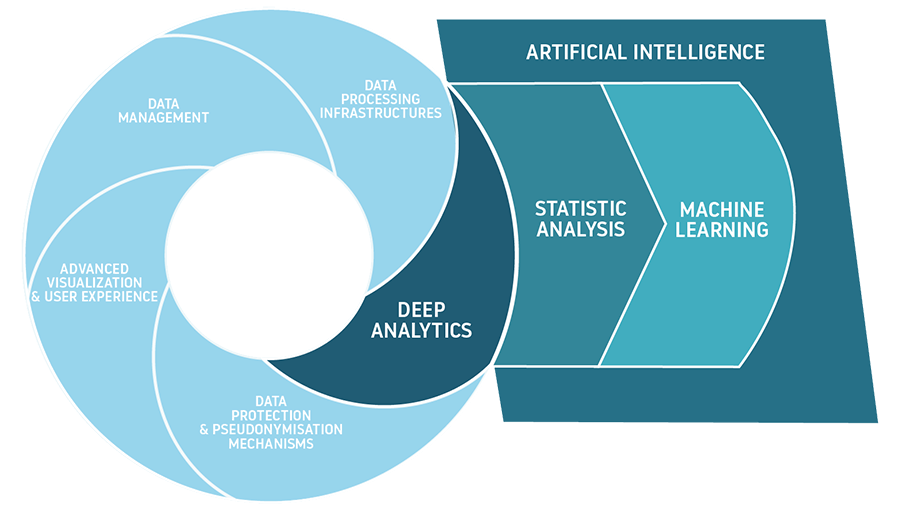
تفاوت بین هوش مصنوعی و علم داده
اکنون که درک گستردهای از تفاوت بین برخی مفاهیم کلیدی هوش مصنوعی دارید، تفاوت دیگری که باید مورد توجه قرار گیرد، تفاوت بین هوش مصنوعی و علم داده است.
علم داده فرآیند و روشی برای استخراج دانش و بینش از حجمهای عظیم دادههای متنوع است. این رشتهی میانرشتهای شامل ریاضیات، تحلیل آماری، تجسم داده، یادگیری ماشین و سایر حوزهها میشود. علم داده این امکان را فراهم میکند تا اطلاعات مرتبط را استخراج کنیم، الگوها را مشاهده کنیم، معنای دادههای عظیم را درک کنیم و بر اساس آنها تصمیماتی اتخاذ کنیم که کسبوکار را هدایت کند. علم داده میتواند از تکنیکهای هوش مصنوعی، مانند الگوریتمهای یادگیری ماشین و مدلهای یادگیری عمیق، برای استخراج معنا و استنتاج از دادهها بهره ببرد.
روابط بین هوش مصنوعی و علم داده وجود دارد، اما یکی زیرمجموعه دیگری نیست. در واقع، علم داده اصطلاحی جامع است که کل روششناسی پردازش داده را در بر میگیرد، در حالی که هوش مصنوعی شامل تمام فناوریهایی است که به کامپیوترها امکان میدهد تا یاد بگیرند چگونه مشکلات را حل کنند و تصمیمات هوشمندانه اتخاذ نمایند. هر دو حوزه میتوانند از دادههای بزرگ بهرهمند شوند، یعنی حجمهای بسیار زیادی از داده.
این درس به بررسی مفاهیم کلیدی هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL) پرداخته و نحوه استفاده از آنها در علم داده را آموزش میدهد. همچنین به نقش الگوریتمهای رگرسیون در تحلیل دادهها اشاره میکند.
واژه نامه هوش مصنوعی و زیرشاخهها
در این قسمت، تعاریف اصلی و پرکاربرد در حوزه هوش مصنوعی و یادگیری ماشینی را گردآوری کردهایم. با مرور این واژهها، دید روشنی از هر مفهوم و ارتباط آن با فرآیند تحلیل داده خواهید یافت.
- هوش مصنوعی (AI): شاخهای از علوم کامپیوتر که سعی دارد سیستمهایی بسازد که رفتارهای شبیه انسان (مثل فکر کردن، یاد گرفتن، تصمیم گرفتن) را تقلید کنند.
- یادگیری ماشین (Machine Learning): زیرمجموعهای از AI است که الگوریتمهایی دارد که از دادهها یاد میگیرند و بدون نیاز به برنامهنویسی مستقیم، پیشبینی انجام میدهند.
- یادگیری عمیق (Deep Learning): زیرمجموعهای از یادگیری ماشین که از شبکههای عصبی چندلایه استفاده میکند تا رفتارهای پیچیدهتری مثل تصمیمگیری انسان را شبیهسازی کند. هر نورون داده را دریافت و با گذر زمان الگوها را یاد میگیرد (مثل تشخیص سگ از گربه). بر خلاف روشهای کلاسیک، یادگیری عمیق با افزایش حجم دادهها، عملکرد بهتری پیدا میکند.
- هوش مصنوعی تولیدی (Generative AI): تمرکز آن روی تولید داده جدید مثل تصویر، موسیقی، متن و کد است، نه فقط تحلیل دادههای موجود. میتواند دادههای مصنوعی بسازد، زمانی که داده واقعی بهاندازه کافی وجود ندارد.
- کاربردهای AI و ML در علم داده: تحلیل پیشبینی (Predictive Analytics): پیشبینی آینده بر اساس الگوهای گذشته.
- توصیهگرها: پیشنهاد محتوا یا کالا به کاربران.
- تشخیص تقلب: شناسایی رفتارهای غیرعادی مثل خریدهای مشکوک.
- تولید داده مصنوعی برای آموزش بهتر مدلها.
- رگرسیون (Regression): تکنیکی آماری برای سنجش رابطه بین متغیرها.
- مثال: بررسی میزان تأثیر متراژ و تعداد اتاقها بر قیمت خانه.
واژه نامه علم داده
در این واژهنامه، تعاریف مختصر و کاربردی مهمترین اصطلاحات حوزه علم داده و هوش مصنوعی گردآوری شده است. با مرور این بخش، میتوانید درک دقیقتری از مفاهیم کلیدی و زبان تخصصی این دو حوزه بهدست آورید.
- شبکه عصبی (Neural Network) مجموعهای از نورونها که داده را پردازش و تصمیمگیری میکند.
- تحلیل بیزی (Bayesian Analysis) بهروزرسانی احتمالها بر اساس دادههای جدید.
- دادهکاوی (Data Mining) استخراج الگوهای پنهان از دادههای زیاد.
- درخت تصمیم (Decision Tree) مدل تصمیمگیری با ساختاری شبیه درخت.
- پنج V بزرگ داده حجم (Volume)، سرعت (Velocity)، تنوع (Variety)، صحت (Veracity)، ارزش (Value).
- تحلیل سبد خرید (Market Basket Analysis) بررسی کالاهایی که اغلب با هم خریداری میشوند.
- پردازش زبان طبیعی (NLP) توانایی کامپیوتر در درک و تولید زبان انسانی.
- داده مصنوعی (Synthetic Data) دادهای ساختگی با ویژگیهایی مشابه داده واقعی.
- دقت و بازیابی (Precision vs. Recall) معیارهایی برای ارزیابی مدلهای دستهبندی.
- کدگذاری خودکار (Coding Automation) نوشتن خودکار کد با استفاده از هوش مصنوعی.
نتیجه گیری
در پایان، روشن است که رابطه علم داده و هوش مصنوعی همچون پازلی تکمیلنشده به یکدیگر وابستهاند: علم داده با فراهم کردن زیرساخت جمعآوری، پاکسازی و تحلیل حجمهای عظیم دادهها، بستر لازم را برای بهکارگیری الگوریتمهای هوش مصنوعی فراهم میآورد و در مقابل، هوش مصنوعی با استفاده از مدلهای یادگیری ماشین و یادگیری عمیق، توانایی تبدیل این دادهها به بینشهای عملی و تصمیمهای هوشمندانه را ممکن میسازد. ادغام این دو حوزه نه تنها دقت پیشبینیها و کیفیت تحلیلها را بهطور چشمگیری ارتقا میدهد، بلکه راه را برای خلق نوآوریهای نوین در صنایع مختلف هموار میکند.
به یاد داشته باشید داده خوب = تصمیمهای بهتر = موفقیت بیشتر در کسبوکار

